RustでWebスクレイピング
RustでWebスクレイピングするCLIツールを作ってみた
相変わらず基礎文法もわからないままChatGPTに質問しまくって実装する
クレートを見繕う
HTMLパーサ
Scraperというクレートが記事もたくさんあってスターも多いのでよさげ
github.com
HTTPリクエスト
スクレイピングするには対象のページからHTMLを取得する必要があるのでそれ用のクレートも用意する
こちらはreqwestが有力っぽい
非同期処理
上二つだけで十分だと思っていたら、Rustはmain関数を非同期処理にできないらしい
今回は1ファイルに手続き的に書く手抜き実装を想定していたのでそれができるようtokioを採用
クレートをプロジェクトに追加
今までは律儀にtmolファイル編集してたけど普通にcargoコマンドで追加できるっぽい(NuGetとかnpmみたいなノリ)
行き当たりばったり学習だとこういう基礎的な所が抜け落ちるのできちんと体系的に学ぼう
cargo add scraper reqwest tokio
なお、tokioに関しては以下のようにCargo.tmolを編集しておかないと一部機能が有効にならないので注意
[dependencies]
tokio = {version = "1.27.0", features = ["full"]}
実装
スクレイピング対象のHTMLを取得
今回はQiitaのトップページから記事タイトルを一覧取得するのを目標にした
なのでhttps://qiita.com/にアクセスしてHTMLを取得する
適当にURL渡したらreqwestでHTTPリクエスト→レスポンスを文字列化→それをHTMLオブジェクトに変換して返す
という感じの関数を作った
async fn get_html(url: &str) -> Result<Html, Box<dyn std::error::Error>> { let res = get(url).await?.text().await?; let html = Html::parse_document(&res); Ok(html) }
HTMLをパース
これでHTMLの取得はできるようになったのでパースして記事タイトルの一覧取得をしてみる
QiitaのHTMLを確認すると各記事のタイトルはarticle→h2→aとタグを辿っていけば取得できそうなのでまずはarticleタグの一覧取得をし、
さらにそれをループ処理してaタグを抽出してその文字列を配列に挿入する関数を作る
fn list_article_title(html: &Html) -> Result<Vec<String>, Box<dyn std::error::Error>> { let mut titles: Vec<String> = Vec::new(); // Stringの配列を宣言 let article_selector = Selector::parse("article").unwrap(); // document.querySelectorAll("article") for article in html.select(&article_selector) { let anchor_selector = Selector::parse("h2 > a").unwrap().into(); // document.querySelector("h2 > a") let anchor = article.select(&anchor_selector).next().unwrap(); let title = anchor.text().collect::<String>(); titles.push(title); } Ok(titles) }
javascriptでdocument.querySelectorAll("article")となるようなSelectorオブジェクトを生成している
動作確認
コード全体
use reqwest::get; use scraper::{Html, Selector}; #[tokio::main] async fn main() -> Result<(), Box<dyn std::error::Error>> { let url = "https://qiita.com/"; let html = get_html(url).await?; let titles = list_article_title(&html)?; for title in titles { println!("{}", title) } Ok(()) } async fn get_html(url: &str) -> Result<Html, Box<dyn std::error::Error>> { let res = get(url).await?.text().await?; let html = Html::parse_document(&res); Ok(html) } fn list_article_title(html: &Html) -> Result<Vec<String>, Box<dyn std::error::Error>> { let mut titles: Vec<String> = Vec::new(); let article_selector = Selector::parse("article").unwrap(); for article in html.select(&article_selector) { let anchor_selector = Selector::parse("h2 > a").unwrap().into(); let anchor = article.select(&anchor_selector).next().unwrap(); let title = anchor.text().collect::<String>(); titles.push(title); } Ok(titles) }
実行してみる
cargo runでこのコードを動かしてみよう
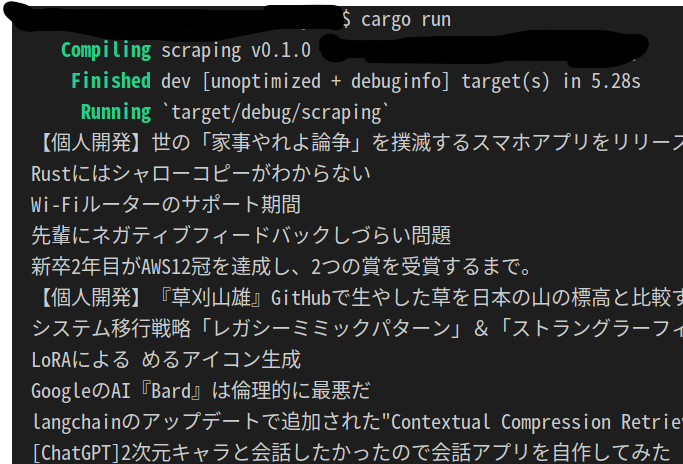
こんな感じでそれっぽいのが表示される
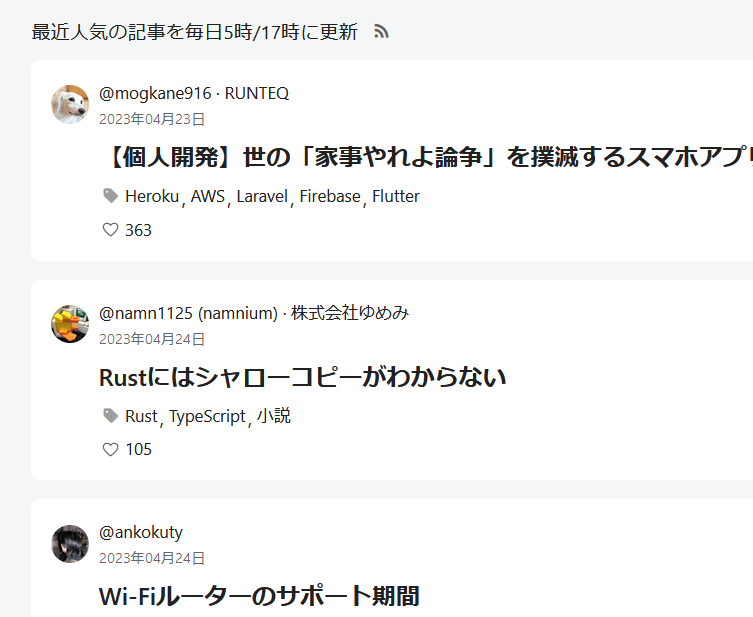
実際にQiitaへアクセスすると期待通りの記事タイトルが取得できているっぽい